WordPiece Tokenization: A BPE Variant
- Atharv Yeolekar
- Jun 28, 2024
- 11 min read

Introduction
WordPiece is a subword tokenization algorithm closely related to Byte Pair Encoding (BPE). Developed by Google, it was initially used for Japanese and Korean voice search, and later became a crucial component in models like BERT, DistilBERT, and other transformer-based architectures.
How WordPiece Relates to BPE
WordPiece and BPE share the same fundamental concept: iteratively merging frequent pairs of characters or subwords to create a vocabulary of subword units. However, WordPiece introduces a key modification in how it selects pairs to merge.
WordPiece Algorithm: A Detailed Breakdown
1. Initialization
Process
Start with a vocabulary of individual characters from the training corpus.
Add special tokens:
[UNK] for unknown tokens
## prefix for subwords that don't start a word
Rationale
Character-level initialization ensures coverage of all possible subwords.
Special tokens help in handling unseen words and maintaining word boundary information.
2. Tokenization of Training Data
Process
Split the training corpus into words.
For each word, create all possible subword combinations.
Rationale
This step creates the initial pool of potential subwords to consider for the vocabulary.
Example
For the word "looking":
l, lo, loo, look, looki, lookin, looking
o, oo, ook, ooki, ookin, ooking
o, ok, oki, okin, oking
k, ki, kin, king
i, in, ing
n, ng
3. Calculating Token Frequencies
Process
Count the frequency of each subword in the training data.
Keep track of which subwords appear at the start of words vs. in the middle/end.
Rationale
Frequency information is crucial for the scoring step.
Distinguishing between word-initial and non-initial subwords helps maintain word structure information.
4. Iterative Merging
This is the core of the algorithm, repeated until the desired vocabulary size is reached or the highest score falls below a threshold.
4.1 Score Calculation
Formula
Score(A, B) = (freq(AB) * len(vocab)) / (freq(A) * freq(B))
Where:
freq(AB) is the frequency of the combined token
len(vocab) is the current vocabulary size
freq(A) and freq(B) are the individual frequencies of A and B
Process Calculate this score for every possible pair of tokens in the current vocabulary.
Rationale
This score approximates the likelihood improvement of the training data if this merge is performed.
Multiplying by len(vocab) gives a slight preference to longer subword units as the vocabulary grows.
4.2 Pair Selection
Process
Select the pair with the highest score.
Rationale
This pair represents the merge that would most improve the model's ability to compress the training data.
4.3 Merging
Process:
Add the merged token to the vocabulary.
If it's not a word-initial subword, add it with the ## prefix.
Update the tokenization of the training data to use this new token where applicable.
Rationale:
This step gradually builds up the vocabulary with the most useful subword units.
The ## prefix helps maintain information about word structure.
4.4 Frequency Update
Process
Update the frequencies of all affected tokens.
This includes the new merged token and any tokens that contained the merged pair.
Rationale
Keeping accurate frequency counts is crucial for subsequent scoring rounds.
5. Stopping Criterion
Options
Reach a predefined vocabulary size.
Continue until the highest merge score falls below a certain threshold.
Rationale
A fixed vocabulary size ensures predictable memory usage and computation time in downstream models.
A score threshold can help ensure that only meaningful merges are performed.
6. Final Vocabulary Construction
Process:
Once stopping criterion is met, finalize the vocabulary.
Ensure all tokens are unique and properly formatted (with ## for non-initial subwords).
Rationale:
The final vocabulary should be clean and ready for use in tokenization tasks.
7. Tokenization Algorithm
Once the WordPiece vocabulary is constructed, tokenization of new text follows these steps:
Split the input text into words.
For each word:
Try to match the longest subword from the vocabulary at the start of the word.
If a match is found, add it to the output and repeat from the next character.
If no match is found, add [UNK] token and move to the next character.
For matches after the first character, use the ## version of the subword.
Rationale
This greedy longest-match approach ensures consistent tokenization.
It balances the use of larger subword units where possible with the ability to fall back to smaller units when needed.
This detailed breakdown of the WordPiece algorithm shows how it builds upon the basic idea of BPE while introducing a more sophisticated scoring mechanism. The algorithm's focus on likelihood improvement rather than simple frequency often results in more linguistically meaningful subword units.
WordPiece Algorithm: End-to-End Example
Note: Hashtags are restricted in the blog, and <h> symbol means #.
Let's use a small corpus to demonstrate the WordPiece algorithm:
Corpus: "the quick brown fox jumps over the lazy dog"
Initial Setup
Basic Vocabulary: ['t', 'h', 'e', ' ', 'q', 'u', 'i', 'c', 'k', 'b', 'r', 'o', 'w', 'n', 'f', 'x', 'j', 'm', 'p', 's', 'v', 'l', 'a', 'z', 'y', 'd', 'g']
Add Special Tokens: ['[UNK]', '<h>t', '<h>h', '<h>e', ' ', '<h>q', '<h>u', '<h>i', '<h>c', '<h>k', '<h>b', '<h>r', '<h>o', '<h>w', '<h>n', '<h>f', '<h>x', '<h>j', '<h>m', '<h>p', '<h>s', '<h>v', '<h>l', '<h>a', '<h>z', '<h>y', '<h>d', '<h>g']
Initial Tokenization: ['t', '<h>h', '<h>e', ' ', 'q', '<h>u', '<h>i', '<h>c', '<h>k', ' ', 'b', '<h>r', '<h>o', '<h>w', '<h>n', ' ', 'f', '<h>o', '<h>x', ' ', 'j', '<h>u', '<h>m', '<h>p', '<h>s', ' ', 'o', '<h>v', '<h>e', '<h>r', ' ', 't', '<h>h', '<h>e', ' ', 'l', '<h>a', '<h>z', '<h>y', ' ', 'd', '<h>o', '<h>g']
Iteration 1
Calculate Scores: For each adjacent pair, calculate the score. Top scores: ('t', '<h>h'): Score = (2 * 29) / (2 * 2) = 14.5 ('<h>h', '<h>e'): Score = (2 * 29) / (2 * 2) = 14.5 ('q', '<h>u'): Score = (1 * 29) / (1 * 1) = 29 ...
Select Highest Score: ('q', '<h>u') with score 29
Merge and Update: o New token: 'qu' o Updated vocabulary: [..., 'qu'] o Updated tokenization: ['t', '<h>h', '<h>e', ' ', 'qu', '<h>i', '<h>c', '<h>k', ' ', 'b', '<h>r', '<h>o', '<h>w', '<h>n', ' ', 'f', '<h>o', '<h>x', ' ', 'j', '<h>u', '<h>m', '<h>p', '<h>s', ' ', 'o', '<h>v', '<h>e', '<h>r', ' ', 't', '<h>h', '<h>e', ' ', 'l', '<h>a', '<h>z', '<h>y', ' ', 'd', '<h>o', '<h>g']
Iteration 2
Calculate Scores: ('t', '<h>h'): Score = (2 * 30) / (2 * 2) = 15 ('<h>h', '<h>e'): Score = (2 * 30) / (2 * 2) = 15 ('qu', '<h>i'): Score = (1 * 30) / (1 * 1) = 30 ...
Select Highest Score: ('qu', '<h>i') with score 30
Merge and Update: o New token: 'qui' o Updated vocabulary: [..., 'qu', 'qui'] o Updated tokenization: ['t', '<h>h', '<h>e', ' ', 'qui', '<h>c', '<h>k', ' ', 'b', '<h>r', '<h>o', '<h>w', '<h>n', ' ', 'f', '<h>o', '<h>x', ' ', 'j', '<h>u', '<h>m', '<h>p', '<h>s', ' ', 'o', '<h>v', '<h>e', '<h>r', ' ', 't', '<h>h', '<h>e', ' ', 'l', '<h>a', '<h>z', '<h>y', ' ', 'd', '<h>o', '<h>g']
Iteration 3
Calculate Scores: o ('t', '<h>h'): Score = (2 * 31) / (2 * 2) = 15.5 ('<h>h', '<h>e'): Score = (2 * 31) / (2 * 2) = 15.5 ('qui', '<h>c'): Score = (1 * 31) / (1* 1) = 31 ...
Select Highest Score: ('qui', '<h>c') with score 31
Merge and Update: o New token: 'quic' o Updated vocabulary: [..., 'qu', 'qui', 'quic'] o Updated tokenization: ['t', '<h>h', '<h>e', ' ', 'quic', '<h>k', ' ', 'b', '<h>r', '<h>o', '<h>w', '<h>n', ' ', 'f', '<h>o', '<h>x', ' ', 'j', '<h>u', '<h>m', '<h>p', '<h>s', ' ', 'o', '<h>v', '<h>e', '<h>r', ' ', 't', '<h>h', '<h>e', ' ', 'l', '<h>a', '<h>z', '<h>y', ' ', 'd', '<h>o', '<h>g']
Subsequent Iterations
The process continues, with likely merges including:
'quic' + '<h>k' → 'quick'
't' + '<h>h' → 'th'
'th' + '<h>e' → 'the'
'b' + '<h>r' → 'br'
'br' + '<h>o' → 'bro'
'bro' + '<h>w' → 'brow' • 'brow' + '<h>n' → 'brown' ...
Final Iterations
As the algorithm progresses, it will start to form complete words and common subwords:
'quick', 'brown', 'jumps', 'over', 'lazy'
Common prefixes and suffixes like '<h>ing', '<h>ed', '<h>s'
Stopping Criterion
The process stops when either:
The desired vocabulary size is reached (e.g., 1000 tokens)
The highest merge score falls below a predetermined threshold
Final Vocabulary
A subset of the final vocabulary might look like:
['[UNK]', 'the', 'quick', 'brown', 'fox', 'jumps', 'over', 'lazy', 'dog', '<h>s', '<h>ing', '<h>ed', ...]
Tokenization with Final Vocabulary
Using this vocabulary, our original sentence would be tokenized as: ['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']
Key Observations
Common words ('the', 'quick', 'brown') become single tokens.
Less common words may be split (e.g., 'jumps' might be 'jump' + '<h>s' in a larger corpus).
The algorithm balances frequency with the improvement in likelihood, leading to linguistically sensible subwords.
The '<h>' prefix helps maintain information about word boundaries and morphology.
This example demonstrates how WordPiece builds its vocabulary iteratively, creating tokens that efficiently represent the training corpus while maintaining linguistic relevance.
WordPiece Tokenization of New Sentences
Let's recall the vocabulary we developed from our previous example: Partial Final Vocabulary: ['[UNK]', 'the', 'quick', 'brown', 'fox', 'jumps', 'over', 'lazy', 'dog', '<h>s', '<h>ing', '<h>ed', 'qu', '<h>i', '<h>ck', 'br', '<h>own', 'ju', '<h>mp', 'la', '<h>zy', ...]
Now, let's tokenize some new sentences using this vocab.
Example 1: Sentence with familiar words
Sentence: "The quick brown dog jumps over the lazy fox" Tokenization: ['the', 'quick', 'brown', 'dog', 'jumps', 'over', 'the', 'lazy', 'fox'] Explanation:
All words in this sentence were present in our original training data.
Each word is tokenized as a single token.
Example 2: Sentence with an unseen word
Sentence: "The quick red fox jumps over the lazy dog" Tokenization: ['the', 'quick', '[UNK]', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog'] Explanation:
"red" is an unseen word, not in our vocabulary.
WordPiece replaces it with the [UNK] token.
All other words are tokenized as in the original sentence.
Example 3: Sentence with a variation of a known word
Sentence: "The quickness of the brown fox surprised the lazy dog" Tokenization: ['the', 'qu', '<h>ick', '<h>ness', 'of', 'the', 'brown', 'fox', '[UNK]', 'the', 'lazy', 'dog'] Explanation:
"quickness" is broken down into known subwords: 'qu' + '<h>ick' + '<h>ness'.
"surprised" is not in our vocabulary and is replaced with [UNK].
Note that 'of' might be tokenized as '[UNK]' if it wasn't in our original vocabulary.
Example 4: Sentence with multiple unseen words
Sentence: "The fastest brown hare leaps over the sleepy cat" Tokenization: ['the', '[UNK]', 'brown', '[UNK]', 'ju', '<h>mp', '<h>s', 'over', 'the', '[UNK]', '[UNK]'] Explanation:
"fastest" is replaced with [UNK] as it's not in our vocabulary.
"hare" is also replaced with [UNK].
"leaps" is broken down into 'ju' + '<h>mp' + '<h>s', as these subwords were likely in our vocabulary from "jumps".
"sleepy" and "cat" are both replaced with [UNK].
Key Observations
Known Words: Words that appeared in the training data are tokenized as single tokens.
Unseen Words: Completely new words are replaced with the [UNK] token.
Subword Utilization: The algorithm tries to break down unknown words into known subwords where possible (e.g., "quickness" into "qu" + "##ick" + "##ness").
Morphological Awareness: The algorithm can handle some variations of known words by using subwords (e.g., "jumps" to tokenize "leaps").
Fallback to [UNK]: When no known subwords can be used, the algorithm falls back to the [UNK] token.
Greedy Longest Match: The tokenization process uses a greedy approach, matching the longest possible subword from left to right.
Preservation of Word Boundaries: The use of '##' for non-initial subwords helps maintain information about word structure.
This demonstrates how WordPiece balances the use of whole words, subwords, and the [UNK] token to handle both seen and unseen words. Its subword approach allows for some generalization to new words, especially those that share subwords with known words, while still gracefully handling completely novel words.
Summary So Far ....

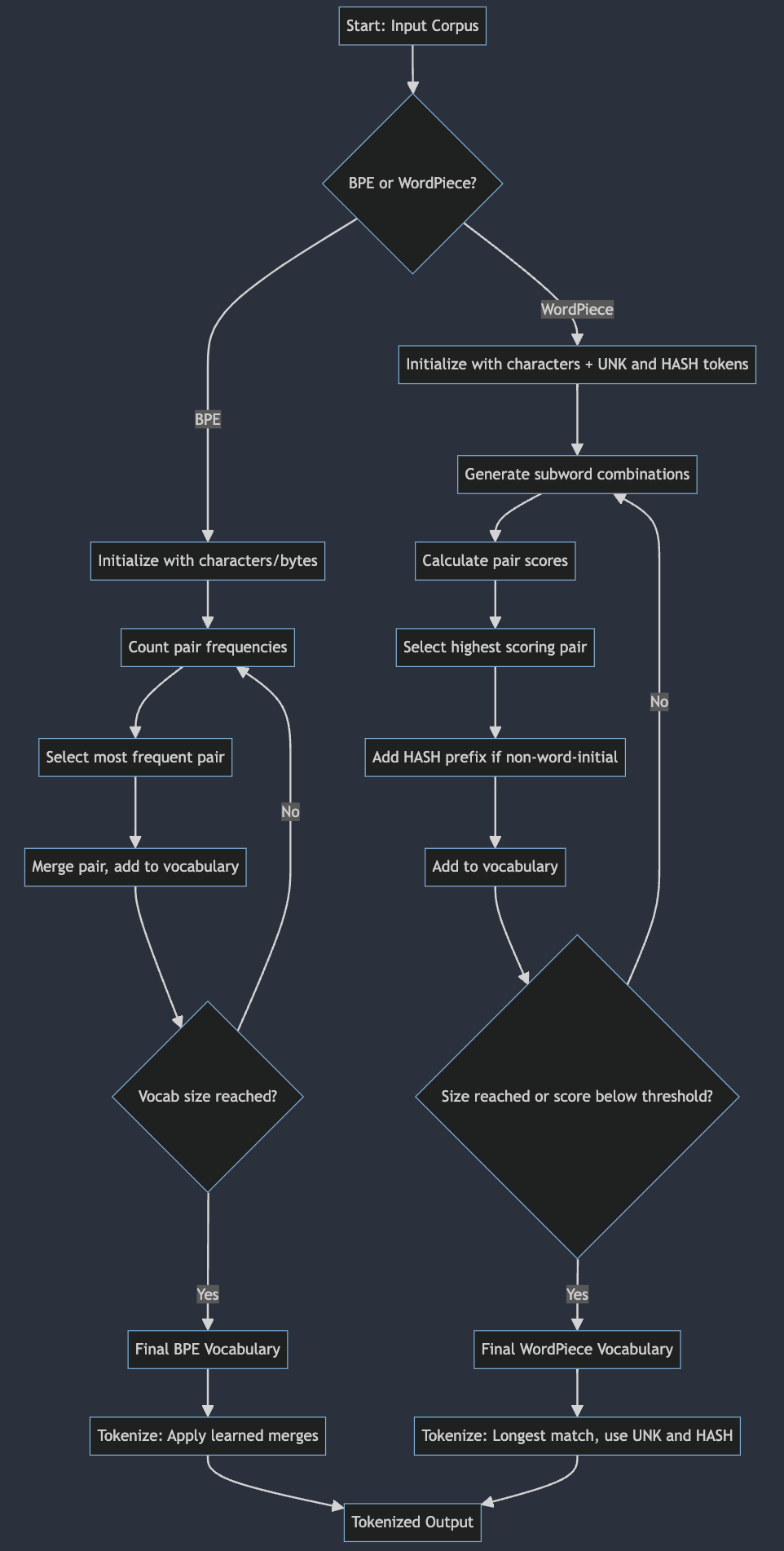
The flowchart illustrates the WordPiece tokenization process, which can be divided into two main phases: the vocabulary building phase and the tokenization phase.
Vocabulary Building Phase
This phase starts with the input corpus and ends with a finalized vocabulary. It involves several key steps:
Initialization: The process begins by creating a base vocabulary and adding special tokens.
Subword Generation: The corpus is split into words, and all possible subword combinations are generated.
Iterative Merging: This is the core of the algorithm, represented by a loop in the flowchart. It involves:
Calculating scores for token pairs
Selecting and merging the highest-scoring pair
Updating the vocabulary and tokenization
Stopping Condition: The loop continues until a predefined criterion is met, such as reaching a target vocabulary size.
Tokenization Phase
Once the vocabulary is built, the flowchart shows how new text is tokenized:
Word-level Processing: The input text is split into words, and each word is processed individually.
Subword Matching: For each word, the algorithm attempts to match the longest subword from the vocabulary.
Token Assignment: Matched subwords are added to the output, while unmatched parts are replaced with an unknown token.
Iteration: This process repeats for each character in a word and for each word in the input.
BPE vs WordPiece: A Comparative Analysis
Key Differences
Initialization
BPE: Initializes the vocabulary with individual characters or bytes.
WordPiece: Starts with characters plus special tokens, specifically UNK (unknown) and HASH (representing ##) for non-initial subwords.
Subword Generation
BPE: Directly counts the frequencies of character pairs in the corpus.
WordPiece: Generates all possible subword combinations before scoring.
Merging Criterion
BPE: Selects and merges the most frequent pair in each iteration.
WordPiece: Calculates scores for pairs and selects the highest scoring pair for merging.
Special Token Usage
BPE: Does not use special tokens in its base algorithm.
WordPiece: Utilizes the HASH prefix (##) for non-word-initial subwords, maintaining word boundary information.
Stopping Criterion
BPE: Typically stops when a predefined vocabulary size is reached.
WordPiece: Can stop based on vocabulary size or when scores fall below a certain threshold.
Tokenization of New Text
BPE: Applies learned merge rules sequentially.
WordPiece: Uses a longest match approach, incorporating UNK for unknown words and HASH for non-initial subwords.
Implications
Vocabulary Composition:
WordPiece's use of special tokens allows for more nuanced representation of word structures.
BPE's approach is simpler but may lose some word boundary information.
Handling of Unknown Words:
WordPiece explicitly handles unknown words with the UNK token.
BPE typically falls back to character-level tokenization for unknown words.
Subword Segmentation:
WordPiece's scoring method often results in more linguistically motivated subwords.
BPE's frequency-based approach can sometimes create less intuitive subword units.
Computational Considerations:
WordPiece's more complex scoring and subword generation might require more computational resources.
BPE's simpler approach may be more computationally efficient during training.
Pros & Cons of WordPiece Tokenization
Pros
Handling of Out-of-Vocabulary Words: Effectively breaks down unknown words into known subwords.
Vocabulary Size Control: Allows for a manageable vocabulary size while maintaining good coverage.
Morphological Awareness: Captures common prefixes, suffixes, and stems, beneficial for morphologically rich languages.
Word Boundary Information: The use of '##' prefix maintains information about word structure.
Balanced Subword Units: Often creates more linguistically sensible subwords compared to pure frequency-based methods.
Improved Performance: Generally leads to better performance in various NLP tasks, especially in multilingual settings.
Efficient Representation: Balances between character-level and word-level representations.
Cons
Deterministic Segmentation: Lacks the ability to handle multiple valid segmentations of the same word.
Static Vocabulary: Once trained, the vocabulary remains fixed, limiting adaptability to new domains or evolving language.
Potential Overfitting: May create subwords that are too specific to the training corpus, affecting generalization.
Inconsistent Tokenization: The same word might be tokenized differently based on context, potentially losing consistency.
Limited Robustness: Struggles with handling variations in spelling or morphology not seen during training.
Language Dependency: Performance can vary significantly across different languages, especially for morphologically rich ones.
Lack of Contextual Awareness: Tokenization is based on frequency and likelihood, not considering the broader context of word usage.
Potential Solutions and Advanced Techniques
BPE Dropout:
Randomly drops merges during tokenization in training.
Improves model robustness by exposing it to different segmentations.
Helps in better handling of rare words and unseen variations.
Subword Regularization:
Samples from multiple possible segmentations during training.
Enhances model's ability to handle different valid subword combinations.
Improves performance especially in low-resource scenarios.
Dynamic BPE:
Allows for vocabulary adaptation during fine-tuning or inference.
Helps in domain adaptation and handling evolving language use.
Addresses the limitation of static vocabularies.
SentencePiece Tokenization:
Treats the input as a sequence of unicode characters.
Language-independent and can handle any unicode characters.
Provides a unified approach for multilingual models.
Contextual Tokenization:
Incorporate surrounding context when deciding on tokenization.
Can lead to more semantically meaningful segmentations.
Addresses the issue of inconsistent tokenization across different contexts.
Hybrid Approaches:
Combine WordPiece with other tokenization methods.
Leverage strengths of different approaches for different parts of vocabulary or different languages.
Adaptive Vocabularies:
Implement methods to update the vocabulary over time.
Allows for better handling of domain shifts and emerging terms.
Conclusion
WordPiece tokenization, while powerful, faces challenges in adaptability and robustness. Advanced techniques like BPE dropout, subword regularization, dynamic BPE, and SentencePiece tokenization address these limitations by introducing flexibility, context-awareness, and adaptability to the tokenization process. These methods enhance model performance across diverse languages and domains, improving generalization and robustness. As NLP continues to evolve, the integration of these advanced tokenization techniques with WordPiece principles promises more effective and versatile language processing capabilities.

Comments